CS285: Lecture 1
Lecture 1: Introduction and Course Overview
Lecture Slides & Video
Abstract
In a reinforcement learning setting, we wouldn’t try to manually solving specify, like, where the robot should grasp object. Instead, the machine themselves will collect the dataset that doesn’t necessarily consist of good examples, but examples that are labeled with the outcomes. So it will be images about what the robot did and whether that led to a failure or success. More generally, we would refer this as a reword function.
A reinforcement learning algorithm, very different from a supervised learning algorithm, is not just trying to copy everything that’s in the data, but trying to use these success and failure labels to figure out what it should do in order to maximize the number of success or to maximize the reward.
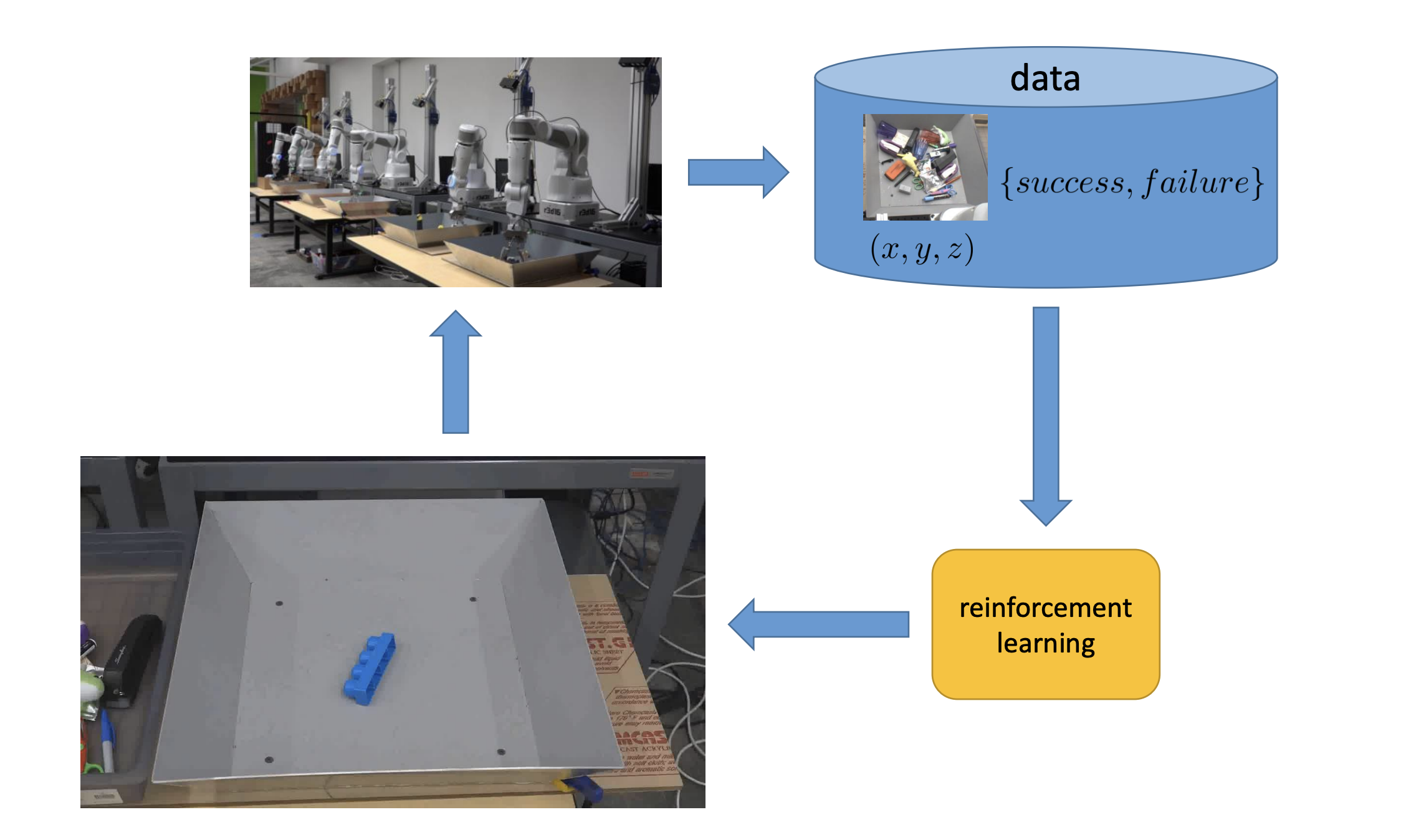
What does reinforcement learning do differently?
The reinforcement learning is impressive because no person had thought of it!
What is reinforcement learning?
- Mathematical formalism for learning-based decision making.
- Approach for learning decision making and control from experience.
How is this different from other machine learning topics?
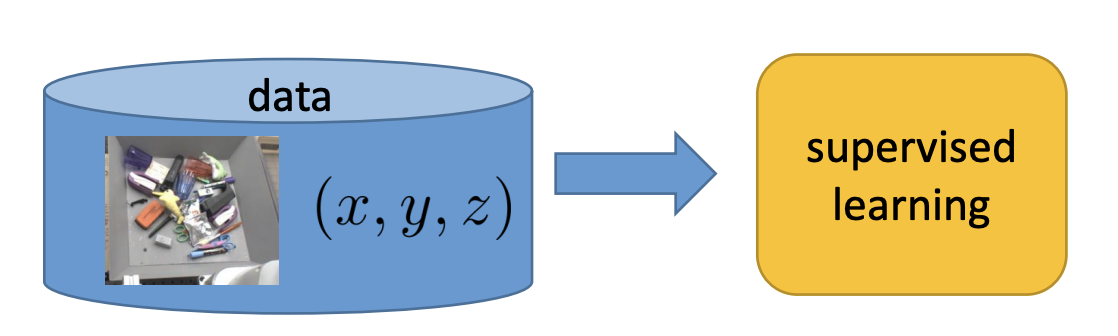
Standard (supervised) machine learning
- i.i.d. data
- known ground truth outputs in training
Reinforcement learning
- Data is not i.i.d.: previous outputs influence future inputs
- Ground truth answer is not known, only known if we succeeded or failed
- more generally, we know the reward
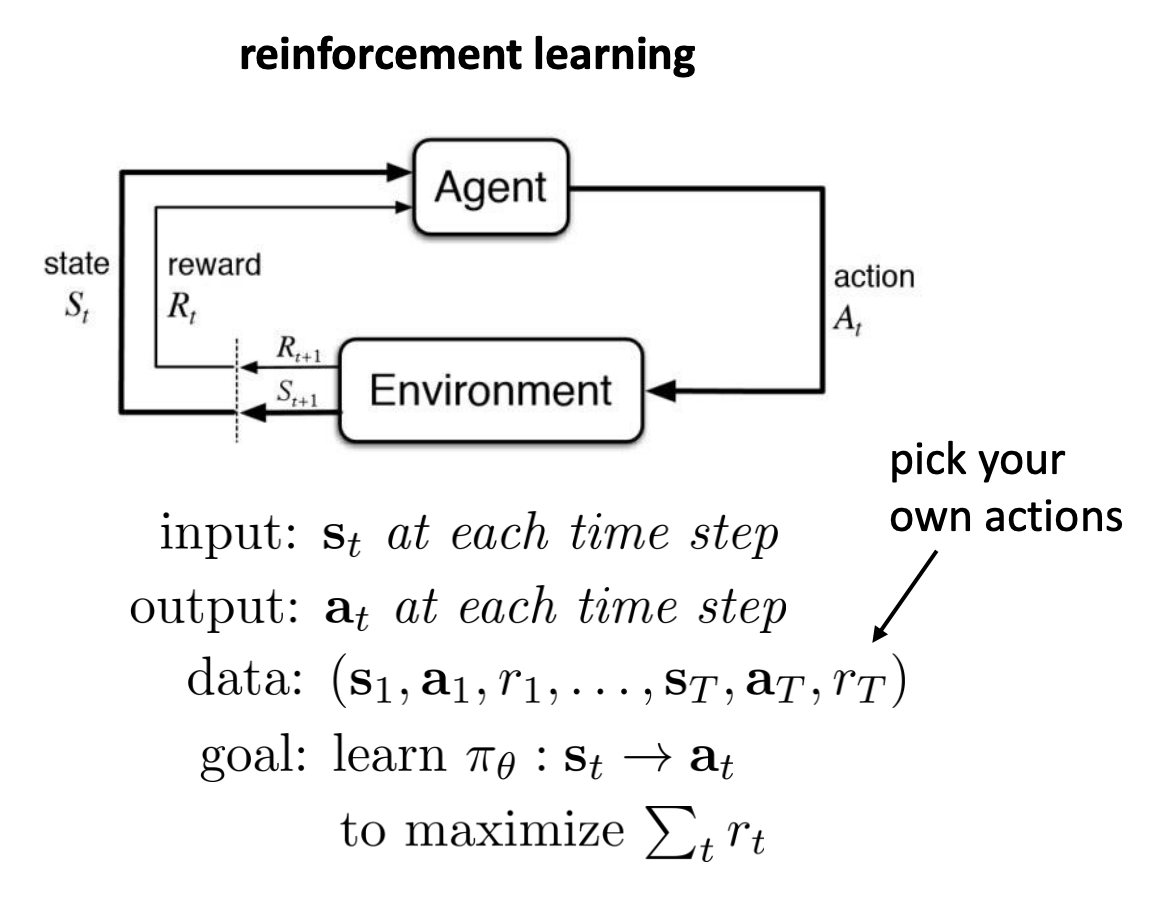
In reinforcement learning, we have a cyclical online learning procedure where an agent interacts with the world. The agent chooses actions $\mathbf{a}_t$ at every point in time and the world responds with the resulting states $\mathbf{s}_{t+1}$ and rewards signal. The reward signal simply indicates how good that state is but it doesn’t necessarily tell you if the action that you just took was a good or bad action.
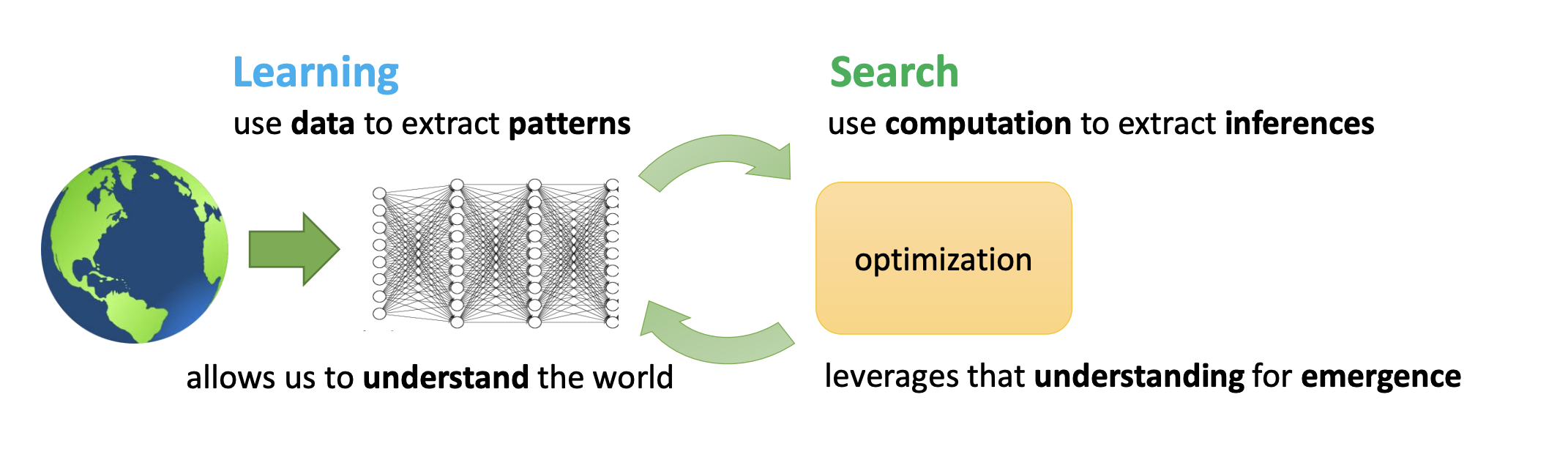
The Bitter Lesson by Rich Sutton
- learning : use data to extract patterns
- Search : use computation to extract inferences
Why do we need machine learning anyway?
A postulate:
We need machine learning for one reason and one reason only — that’s to produce adaptable and complex decisions.
It’s not a problem of prediction, but a problem of decision making.
Where do rewards come from?
As human agents, we are accustomed to operating with rewards that are so sparse that we only experience them once or twice in a lifetime, if at all.
It’s obvious that the rewards of lots of impressive things that humans do are so delayed that it is very difficult to imagine learning from the reward signal.
Are there other forms of supervision?
- Learning from demonstrations
- Directly copying observed behavior
- Inferring rewards from observed behavior (inverse reinforcement learning)
- Learning from observing the world
- Learning to predict
- Unsupervised learning
- Learning from other task
- Transfer learning
- Meta-learning: learning to learn
How do we build intelligent machines?
Learning as the basic of intelligence
- Some things we could all do (e.g. walking)
- Some things we can only learn (e.g. driving a car)
- We can learn a huge variety of things, including very difficult things
- Therefore our learning mechanism(s) are likely powerful enough to do everything we associate with intelligence
- But it may still be very convenient to “hard-code” a few really important bits
A single algorithm?
- An algorithm for each “module”?
- Or a single flexible algorithm?
What must that single algorithm do?
- Interpret rich sensory inputs
- Choose complex actions
Why deep reinforcement learning?
- Deep = scalable learning from large, complex datasets
- Reinforcement learning = optimization
What challenges still remains?
- We have great methods that can learn from huge amounts of data
- We have great optimization methods for RL
- We don’t (yet) have amazing methods that both use data and RL
- Humans can learn incredibly quickly, deep RL methods are usually slow
- Humans reuse past knowledge, transfer learning in RL is an open problem
- Not clear what the reward function should be
- Not clear what the role of prediction should be
Instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain.
— Alan Turing